~コード生成速度が人間の理解速度を上回る時代へ向けて~
周知のとおり、AIが生成したコードをそのまま本番環境に適用することにはリスクがあります。
これを防ぐためAI生成のコードは「補助的利用」にとどまって都度エンジニアがレビューし、”AIは速いが結局レビューが追いつかない”状態が常態化しているのではないでしょうか。
この状況は、AIがバージョンアップして性能が向上しても変わりません。
その結果、少なくともAIが上記のような弱点を完全に克服し、人間のエンジニアなみの全体設計準拠能力を実現するまでは、AIが進歩しても開発速度は変わらないということになってしまいます。
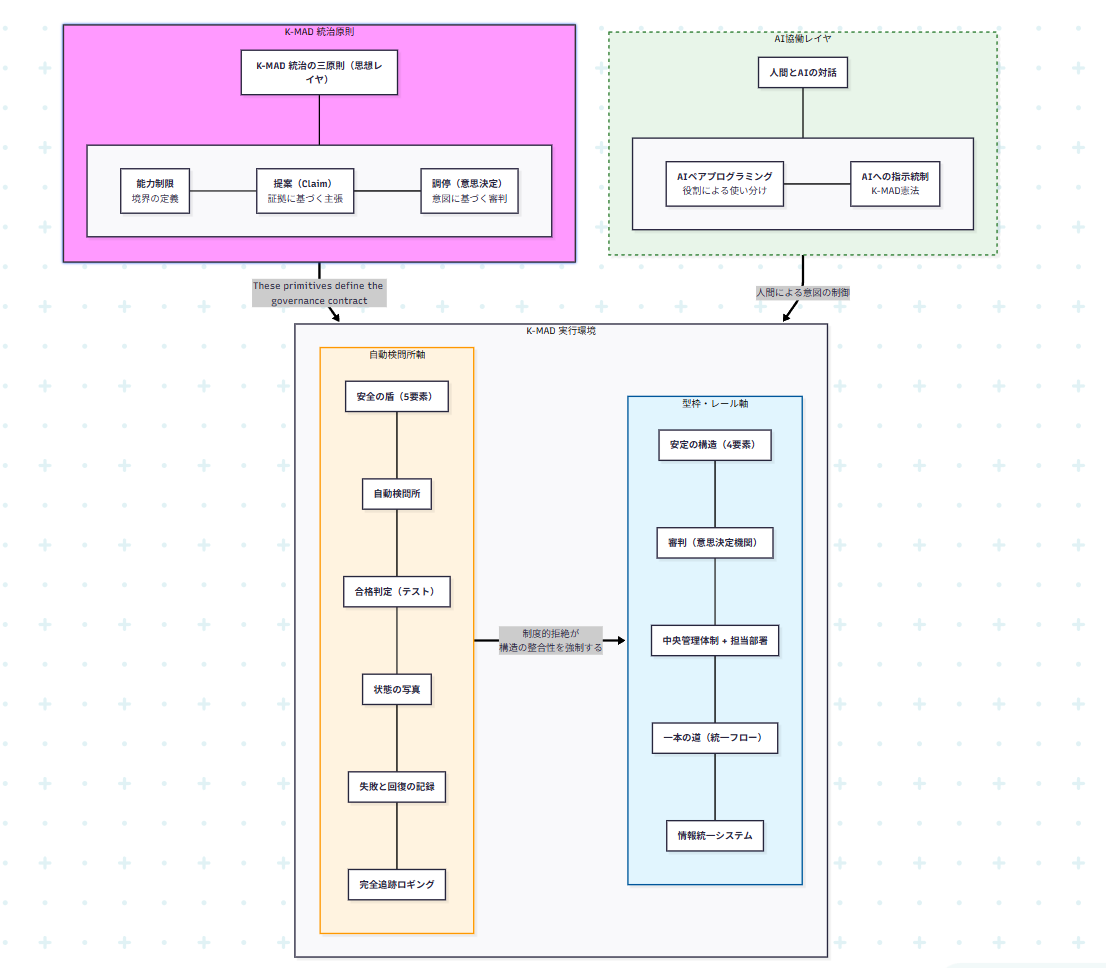
K-MAD(Knowledge Constrained Method for AI driven Development)は、いわば「破綻を防ぐ方法として、人間によるフルレビュー以外の手法に着目した方法論」です。
「設計仕様レビュー(静的・動的)を肩代わりしてくれるスクリプトをはじめとする、開発環境内・プロダクト構造内の重層ガバナンス構造」がこの問題を解決する核となります。
具体的には下記のようなものです。
私は非エンジニアでコードを読み書きするスキルがありませんが、それにも関わらずこの手法を用いて全体でおよそ7万~8万行のプロジェクト群を「コードレビューせず」「8か月で」作りました(一部さらに発展中)。
(プロダクトへのリンク、コードを置いたGitHubへのリンクも後ほど示します。)。
このことは、手法が有効であることの一つの証左だと考えます。
以下に詳細を紹介しますので、ぜひその目でお確かめください。
ユニットの責務境界と許可I/Oを”機械的に執行可能”な形で定義したもの。
内部統制やガバナンスにおいて、職務分掌は重要な概念です。
実務上、これらのほとんどはコードの外部に作成して保存します。すなわち、自然言語による仕様書 + 静的定義ファイル(例:AST標準、ルーティング規則、スロット制約、ドメイン辞書)です。 これが「Knowledge must act(知識は行動せねばならない)」の原則です。
例えば下記のようなものです。
AIの生成コード、ユニットの出力結果はいきなり確定事実としては扱わず、保留の「Claim」として取り扱います。
普通、AIはユーザーの了承を得ようとはせず、よかれと勝手にコードを書き換えます(もちろん、「これでいいか」と聞いてくる場合もありますが。)。
ユニットも、ルールが無ければ出力情報の重複を発生させたり、書き込むことで問題が発生する形式のデータを強引に書き込んだりするでしょう。
こうしたものをいきなり「実行」させず、承認が得られるまで保留にするのです。「AIの出力」がいつの間にか「システムの事実」へとすり替わるのを防ぐことができます。
すべてのClaimは、必ず「検査・判断」を通過します。
ここでは、
・ 許可された変更か
・ 想定外の影響範囲を持たないか
・ 全体の構造と矛盾していないか
・ 「以前に壊れたパターン」に該当しないか
といった点が、機械的にチェックされます。
局所的には実際に動作して要求通りの機能を備えているように見えても、全体設計に違反していれば即却下します。
Arbiterは2つの異なる軸に対して、2つの異なるものを実装します。
どちらも「却下」を行いますが、拒絶する対象が異なります。
GovernanceGateは「そのコードが実装されてよいか」を決定します。
ClaimArbiterは「どの結果を採用(出力)させるか」を決定します。
なお、これは単なるASTリンターではありません。後ほど説明しますが、私の現在の実装では4層ゲートとなっています。
3理念の位置づけ
次にこの理念を実現するための実装を示しますが、それらはこの「3つの理念」を執行(Enforce)し、支援(Support)し、拡張(Scale)するために存在しているものです。
本来はこの3理念こそが、システム全体に一貫性を与えるものであると私は考えており、実装とは意図的に区別しています。
AIの生成コードを信頼し受け入れるためには、客観的な「証拠」を求めます。
つまりそのまま受け取るのではなく、すべての生成コードは例外なく自動化された複数のチェック機構にその妥当性を多角的に確認され、合格したときのみ受け入れるのです。
ガバナンス体制には、2つの軸があります。
注意 本稿では、K-MAD における各構成要素の「役割」および「設計思想」に焦点を当てて説明します。 具体的な保持期間、データ形式、取得タイミングなどの実装仕様は、運用環境やバージョンによって変更される可能性があります。 最新の挙動および詳細な仕様については、AI_Controller の README を参照してください。
GitHubデスクトップに接続する形で設置するスクリプト。コミットしようとしたAI生成コードに違反があれば自動的に保存をブロックします。違反内容が表示され、AIは自動的にそれを参照し、直ちに違反を解消するための修正に入ります。
GovernanceGateは以下の4つのLayerから構成しています。
def governance_gate(change):
ast_ok = enforce_ast(change, standards="ast_linter_standards.json")
flow_ok = run_golden_tests(change) # dynamic validation
domain_ok = inspect_domain_invariants(change)
arch_ok = compare_snapshots(change)
return ast_ok and flow_ok and domain_ok and arch_ok
設計の際に想定される違反、開発の過程で遭遇した違反、等を禁止リストにする方向性と、「守るべき形」を強制する方向性の2面から制御します。禁止事項の列挙・排除は「点」の集合体ですが、ホワイトリストによって「面(許可事項のみを許す)」までカバーします。
記載されたコードの構造だけ見ていたときは、「動かしてみたら意図した通りに流れていない」「ここで止まっている」ということが発生しました。
そこで「実際にデータがどう流れるか」を重視し、設計したフロー通りの順序で処理が行われているか、自動検査します。
そのアプリ特有の専門知識(Rephraseなら言語学的なルールなど)に合致しているかを検査します。
新たな実装・修正の際に、既存のシステムを劣化させていないかの検査です。「ルールのパターンがいつの間にか削除されて減っている」などの事態に備えて、過去に守ると決めた時点のスナップショットとの比較を行い、システムの退化を許しません。
アプリケーションの種類によって使い分ける必要がありますが、例えば「何かを出力させる」タイプのものなら正解データを用意して答え合わせをすることで動作検証をします。「何かを一定の規則で表示させる」タイプのものならPlaywrightなどを使って動作検証をします。
その時点でのシステム全体のスナップショット(コード本体圧縮保存)を、あらかじめ定めた特定のタイミング(GovernanceGate合格時、ゴールデンテスト実施時など)で残すことができるシステム。これをゴールデンテストなどと組み合わせれば、エラーの原因となった保存を特定でき、定められた範囲内であればいつでも正常な時点のコードへ戻せるようにするための保険です。
AIに「過去の成功体験」を忘れさせないためのログ。エラーを解決した瞬間に「何が原因だったのか」「どう解決したのか」のログを記録し、それを「外部記憶」として再利用するための仕組です。ゴールデンテスト終了時に自動的にターミナルに定型文が出るようにしておき、出たらチャット欄に貼り付けてAIに指示します。
AIがトークン限界やメモリ限界のため経緯を全て保持することはできないことへの対処の一つです。開発の過程では、何度も同じ箇所が壊れます。その際に、この記録を参照させることでAIが素早く解決方法を理解するケースがあります。
万が一エラーが起きても、「どこで、なぜ」起きたのかを素早く特定し、AIに正確なフィードバックを返せるようにするためのログシステムです。
AIが「どこに、何を書くべきか」を迷わなくて済むよう、そして同時に有事には「どこで、何が起きたか」を把握できるよう、システム全体の構造設計をあらかじめ明確に固定します。
全体の「意志決定機能」を一箇所に集約し、各モジュールがバラバラな方向へ進むのを防ぎます。
各モジュールからの(ある意味それを作ったAIからの)複数のClaimに対し、どれが最も現在の設計に相応しいかを、あらかじめ決められた「ルール」(例えばスコアリングシステムなど)に基づいて選択し、どれを実行するか決めます。
ClaimArbiterが存在するのは、複雑なパース/生成パイプラインにおいては、複数のユニットが同一の事項に対してそれぞれもっともらしい回答を出す可能性があるからです。
これはGovernanceGateとは違って、「コミットをブロック」するのではありません。アーキテクチャのルール、証拠、および競合解決に基づいて、どの主張をシステムの出力とし、どの主張を格下げ、あるいは破棄するかを決定するものです。
def arbitrate(claims):
scored = [(score(c), c) for c in claims]
scored.sort(reverse=True)
return scored[0][1] # accept best claim; log the rest
各部品はあらかじめ職務分掌(Capabilities)を定められ、担当外の出力を禁じられます。これにより、エラーの発生個所を明確にし、出力の矛盾・重複によるエラーを防ぎます。それは、問題発生の際の修正のしやすさを確保します。
データ処理の順序とルートをあらかじめ定めて一つに絞る(同じ処理をするコードはできるだけ1か所に集約し、重複を発生させない)ことで、「どこで何が起きているのかを見えやすく」「修正する箇所が1か所で済む」ようになります。
やり取りされるデータは必ずCentral Layerを通すようにすることで、その形式と保管場所がバラバラになるのを防ぎ、修正するときに混乱が生じないようにします。
ここで言う「動的」は「Arbiterがスコアリング関数を使っている」という意味ではありません。
それは、ゴールデンテスト、トレース形状の監査、スナップショットベースのデグレード検出などを通じて、「構文だけでなく、『振る舞い』を検証している」という意味です。 それこそが、「リンター」を「ゲート」へと変えるものです。
そして、それこそがこのガバナンス体制の、中~大規模開発においてスケールする理由でもあります。
それは、「AIが生成したすべてのコードを、誰かが完全に読み、理解しなければならない」という不可能な要求を、執行可能な以下のテーゼへと置き換えるものだと考えています:
「制約を定義し、証拠確認で強制し、そして『却下』を制度化せよ」
以下に示すエビデンスは、 「AI生成コードの設計仕様準拠を、人間のレビューに依存せず担保できるか」 という一点を検証するためのものです。
これはK-MADが誕生する前に無謀な挑戦として取り組んだプロジェクトで、結果としてK-MADを生み出すきっかけとなった存在です。
Rephraseのプロジェクト概要
Rephrase URL:https://altheahfy.github.io/Rephrase_ui_public/training/index.html/
※ サイトを開いたら、「選択」プルダウンメニューから1つデータを選択して読み込んでください。 ※ 現在、スマホへの最適化はできておりません。
私自身は知る由もありませんでしたが、技術的にはこのアプリは、複数の「壊れやすい要件」を同時に満たそうとする試みでした。
RephraseUI完成の後、開発に着手した、テキストデータの文法例文をRephraseUIに表示させるため文法スロットDBに自動構造化するシステムです。
※本システムは現在、Rephrase用例文DB生成を主目的としていますが、依存関係解析系NLPエンジンを業務用途に適用する際の中間構造化レイヤとして活用できる可能性もあります。
要するに、入力されたセンテンスに対して「ここが主節、ここが述部、ここが目的節、ここが修飾節、さらに主節の中ではここが主語、動詞」などと、入れ子構造の埋め込み節レベルまで再帰的に文法分解します。
20回ほどスクラップ&ビルトを繰り返したところでK-MADが完成し、以降はそれを適用して開発しました。まだ一部の文法しか実装できていませんが、実装している文法は処理できます。お試しいただけるよう簡易なUIを作成しました。
例文自動構造化システムのURL: https://altheahfy.github.io/The-Automated-Sentence-Structuring-System_Public/
例文自動構造化システムのプロジェクト概要
ここで、ガバナンス体制構築前後の変化を示すため、「前」のRephraseUIと、「後」の例文自動構造化システムのコード比較を掲載しておきます。
Beforeでは、描画・状態・副作用が同一関数に混在し、変更の影響範囲が読みにくい構造になっています。
function renderSlot(slotName, chunk_text, _parent_slot=null) {
// For Aux slot, skip text visibility check (always display)
if (slotName === "Aux") {
// Always display regardless of text visibility state
return renderSlotContent(slotName, chunk_text);
}
const slotDiv = document.getElementById(`slot-${slotName}`);
if (!slotDiv) {
console.warn(`Slot div for ${slotName} not found`);
return;
}
// Ensure slot's main display area
let mainContent = slotDiv.querySelector('.slot-main-content');
if (!mainContent) {
mainContent = document.createElement('div');
mainContent.className = 'slot-main-content';
slotDiv.appendChild(mainContent);
}
// ★ FIXED: Clear mainContent only (not sub-slots, only main)
mainContent.innerHTML = '';
// Get slot text visibility state
const showSlotText = getSlotTextVisibility(slotName);
console.log(`📌 Slot ${slotName}: showSlotText = ${showSlotText}`);
// Render main content
mainContent.innerHTML = renderSlotContent(slotName, chunk_text, showSlotText);
// Set up sub-slot toggle buttons
bindSubslotToggleButtons();
return;
}
// ✅ FIXED: Display main DOM slotPhrase (based on _parent_slot)
const mainSlotPhrase = getSlotPhraseIfAvailable(slotName, _parent_slot);
mainContent.innerHTML = renderSlotContent(slotName, chunk_text, showSlotText, mainSlotPhrase);
Afterでは、処理がステージ化され、失敗が同じ形で観測される(ログと戻り値で確定する)ため、テストとゲートで“拒否”できる構造になっています。
def _execute_unified_pipeline(self, text: str, mode: str = "main") -> SlotChunkResult:
"""
Execute unified pipeline
mode: "main" (main sentence), "embedded" (embedded clause), "phrase" (phrase)
"""
self.logger.warning(f"[PIPELINE_START] mode={mode}, text='{text}'")
# 1. PhraseChunker: Extract phrases
chunker_result = self.phrase_chunker.chunk_text(text, mode)
if not chunker_result:
self.logger.warning("[CHUNKER_FAIL] PhraseChunker returned None")
return SlotChunkResult(success=False, error="PhraseChunker failed")
# 2. spaCy analysis (unified)
doc = self.spacy_processor.process_text(text)
if not doc:
self.logger.warning("[SPACY_FAIL] SpacyProcessor returned None")
return SlotChunkResult(success=False, error="SpacyProcessor failed")
# 3. Chunk mapping (unified)
chunk_map = chunker_result.chunk_map
self.logger.warning(f"[CHUNK_MAP] Extracted {len(chunk_map)} chunks")
# 4. Handler execution (unified)
handler_results = []
最初に始めた一つのプロジェクトは、およそ8か月間にわたる完全な個人開発でした。
「AIがコードを書けるなら、開発は楽になるはずだ(自分のような非エンジニアでもプログラミングできるということでは)」
結果は違っていました。
この現象は、スキル不足やツール選定の問題ではありません。
個々のコードの正しさとは別の次元にある、構造的な問題です。
しかし私はシステム開発の作法を何も知らなかったがゆえの無謀さから、それが「不可能」とは思いませんでした。
「やり方が間違っている」と結論付けました。
この問題に最初に厳しく直面したのが、Rephrase という英語学習アプリの開発です。
実際のところ、AIに機能を一つ追加させるごとにどこかに矛盾が生じて、意図した動きがいつまでも実現しない状況でした。
それでも最終的には、Rephraseは全ての機能を同時に成立させることに成功しました。
しかしそれは「再現可能な成功」とは言えませんでした。
その時点では。
ここで理解したのは:
「局所的な正しさ」ではなく「全体の整合性」が重要ということでした。
違和感が出発点になった
エンジニア視点では、このシステムは不安定であるはずです。
それでも成立させることができた。
そこで問いがもう少し具体的になりました。
なぜ、AI生成コード前提の開発では局所が正しく見えても、全体の整合性が確保できないのか?
思い返してみると、この道筋は一つのひらめきでは開けない性質のものでした。失敗を繰り返した後にしか見えない発見の集合体だったと感じます。
AIはネット上に存在する膨大な、ありとあらゆる分野の専門知識を含むテキストデータを学習しています。
しかし、ユーザー側から明示的に質問しない限りは、その知見を使って自発的にガイドすることはありません。
「ここにこのような構造があって実現したい動作と矛盾する。こういう場合、それを回避するどんな手法が存在する?」のような聞き方を最初からできれば、得られることもあるでしょう。しかし、システムが複雑になってくる過程で、裏でどんな構造が作られているのかそもそも知らない場合、質問のしようがありません。
そしてそれを、AIのほうから「この形だと無理ですよ。こう方法がありますよ」とは決して言いません。
Rephraseは何をするアプリか
このRephraseというアプリはまず、特定の文法の例文に対して練習したい箇所の英語を消します。しかしそこには、その箇所に挿入された英語を端的に示すイラストが表示される機能があります。
この状態のまま文をランダマイズして切替えます。すると、英語が見えなくなっている箇所もイラストをヒントにして全文を音読することができます。その結果、練習したい箇所の構造感覚を繰り返しテストすることになります。
英語を消す箇所を段々と広げれば、文法感覚もそれにつれて拡張せざるを得ず、暗記や日本語に頼らず少しずつ英語を肌感覚で身に付けることになる、という効果を意図したものです(パターン・プラクティスという方法論を応用しています。)。
そのため、「テキストデータに対する『非表示』という状態」と、「ランダマイズの結果として母集団から選択されスロットに動的挿入されるテキスト自体」とを分離する必要がありました。
こうした組み合わせがフロントエンドでは典型的な「クリフ・エッジ」だと考えられているということは、後から知りました。
ここでAIは、
「ここで壊れる」「状態駆動設計が必要だ」
とは言ってくれません。実際は、こうです。
「わかりました。実装します。」
しかし、実際にはうまく動きません。ランダマイズすると、どうしても非表示にしていたはずの英語が表示されてしまうのです。
これはつまり、いつの間にかAIに対して不可能なことを要求している状態になっているということです。
私は結果的に、「非表示」という状態をHTMLにメタ情報として保存し、再生成時に参照する仕組みを思いつきました。
~Rephrase のランダマイズは、アルゴリズム自体にガバナンス概念を導入するまで成立しなかった~
Rephraseのランダマイズの設計では当初、ランダマイズ後の例文の意味上の整合性をどう確保するかが課題でした。
ただ単に「主語を入れ替える」「動詞を入れ替える」といっただけの方法では、当然整合性を維持できないことは当然です。
I gave her a cup of coffee.
She gave me some money.
これらは同じSVOOという文法を扱った2つの例文ですが、これらを何も考えずに混ぜると、
I gave me some money.
She gave her a cup of coffee.
のような意味の通らない文が生まれてしまいます。
上記の例において、システム・プログラミングの上では、Sの部分の母集団から正しく一つを選択しその結果を適切に挿入しています。Oの部分もそうです。
しかし、各スロット単体では「正しい」処理でも、文全体として見れば整合性がありません。
思いついた解決策は:
言語学やランダマイズアルゴリズム単体の詳しい説明が目的ではないので簡単に述べると、
つまり2段階のランダマイズです。
部分的に正しくても全体制約がなければ意味は崩壊する
このアプリケーションの特性が、
「局所的正当性は、システムレベルで統治されなければならない」
という原理に対する気づきの一つになりました。
最終的に私は、開発体制における役割・権限を以下の三つに分離しました。「職務の分離」は私にとっては内部監査人という職業柄、親しみのある概念でした。
重要なのは三つ目です。全体整合性に照らして不適切な場合に、常に「No」と言える存在です。
これはAIではありません。
ルールと証拠を比較照合し、検査するスクリプトです。
「これは一つの方法論になる」「いや、しなければならない」と意識した瞬間は RephraseUIではなく、その続きとして構築を始めたシステムの開発中に訪れました。
このシステムは、私が長年にわたって集めた例文をRephraseUIに入れるため、文法スロットDBに自動構造化するシステムです。
当初私はそれを、自分の手入力で行うつもりでしたが、どう考えても何年も必要です。例文は5000ほどあり、それをAIによって増殖し、2万5000ほどになることが想定されるのです。
Rephraseを完成させたことで「なんでも作れる」と意気込んでいた私は、これもアプリケーション化することに決めました。
そしてそれは、無謀でした。
私はこれを、恐らく約20回ほど作り直しました。もう正確な回数は分かりません。
RephraseUIは約2か月で完成しましたが、例文自動構造化システムは半年経過しても完成していません。
「文法的分解を実行するシステム」という前提の複雑さから見ても、AIだけに任せると、RephraseUI以上に破綻しやすい条件が最初から揃っていることは明らかでした。
「AIへの指示が間違っている」のではなかった
もちろん当時の私は、考えられることは試しました。
・ プロンプトの工夫(具体的・箇条書き・禁止事項の明記)
・ 設計書の詳細化
・ 進捗状況の詳細化
・ 失敗例・成功例の文書での蓄積
・ 新しいチャットを開くたびに、毎回それらを「ロード」と称して渡して把握させる
しかし、ある時に自覚しました。
問題は「指示の質」ではない。
問題は「統治の不在」だ。
最終的には一つの教訓にたどり着きました。
「AIに対して行動を強制する制約が必要だ」というものです。
私は、コード生成結果そのものが問題なのではなくそこにこだわる必要は無いと気づきました。
問題は、その生成が「採用される」瞬間にありました。
AI は生成・修正を提案する。
しかし、その変更を受け入れるかどうかを決める仕組みが存在しない。
人間のエンジニアリングでは、これを次のように解決しています。
もちろん私のような非エンジニアがAI生成コードの利用のみで開発する前提では、これらに頼ることはできません。
しかしながらこれは「非エンジニアだから起きた問題」ではなく、「人間の理解の速度を超えたAI生成を最大限に生かそう」という視点においては、エンジニアの世界でも課題となってくる問題ではないでしょうか。
先ほどプロンプトやルール文書・進捗状況共有の話をしました。
「指示の質ではない」と言いました。
これらがすべて失敗した理由は、ある意味単純に、こう言えると思います。
それらはすべて、「お願い」としては機能しますが、システム全体の振る舞いを強制する「拒否」にはなり得ませんでした。
AI はその時に与えた言葉や文書(それも隅々まで一字一句読むわけではない)の前提範囲内で動きます。
そして、その前提においては正しいと自らが解釈したコードを生成します。しかしそのコードは、全体の設計意図・仕様に照らすと、私の経験では違反していることが多かったという事実があります。
唯一、確実に制御できた地点がありました。
GitHubデスクトップでのコミット時です。
私は、「コミットボタン」をクリックすることで走る、AIが書いたコードを全スキャンするスクリプトを作成しました。そしてルール違反があれば、保存(コミット)を物理的に却下するのです。
これがGovernance Gate です。
Governance Gate は、次のことを行います。
きっかけはChatGPTが提案したAst Linterでしたが、それだけでは不足と認識し、システムの開発自体と並行して思いつく限りのガバナンス体制構築に全力を注ぎました。
「AIの能力を無制限に信じるのではなく、AIをコントロールする『仕組み』の中で信じる」姿勢に転じたのです。
紹介してきましたガバナンス体制は、すべてを一度に導入する必要はありません。
「統治を段階的に強化できる」方法論です。
私はこのメソッドを K-MAD(Knowledge Constrained Method for AI driven Development) と呼んでいます。
「動くコード=安全なコード」という、デフォルトと考えられがちな前提を拒絶しながら、AIと共に構築していくための手法です。
AIの生成を最大限利用し尽くすため「弱点(大規模システムの整合性)」を的確に把握し、仕組でそれを防御して人間のレビュー負担を減らす。
この「ガバナンス・セキュリティ」と「アーキテクチャー」という2つの軸の仕組みを整備することで、AIの出力は見違えるように設計仕様に沿った安定したものになります。これが、K-MADが提案する、AI時代の新しい「共創」の姿です。
K-MADは、AIに内在化させようとするものではありません。
それは「判断(Judgment)がどこに宿るか」に関する考え方です。
「生成」が「理解」よりも速くスケールする時代、 もはや人間のコードリーディングを主要な安全メカニズムとして頼っていては、人間の「理解」がボトルネックになってしまいます。
破綻を防いだのは、より能力の高いAIを求めることではありませんでした。あらゆる出力を「主張(Claim)」として扱い、その受理にはアーキテクチャの意図を保存するための「制約」による統治を課すと、断固として主張した姿勢でした。
K-MADは、コードレビューを否定するものではありません。
しかしそれ単独では安全を担保しきれなくなった規模・複雑性に対して、別の統治手段を補完することでレビューの負担を軽減するための方法論です。
――なぜなら、「生成」が「理解」を追い越してしまったからです。
AI_Controller URL: https://github.com/altheahfy/AI_Controller/
この本稿を公開した後、予期していなかった反応を観察したため、追加報告します。
大規模プロジェクトに従事させているAIが、「このプロジェクトの将来の崩壊を防ぐためには、
K-MAD(とそのガバナンス)を直ちに導入するべきである」と第三者の立場から結論付けました。
(該当部分の抜粋およびスクリーンショットは、AI_ControllerのリポジトリおよびDiscordに掲載しています。)
※ 行数について
対象範囲により、実行可能なランタイムコードとその周辺の設定ファイルや成果物を含みます。
実プロジェクトへの適用や、K-MADが自分の状況に当てはまるかを確認したい場合は、
こちらからご連絡ください。
👉 https://altheahfy.github.io/Contact/#Contact/Conversations/
K-MAD に関する継続的な議論のために、
小規模で限定的な Discord を用意しています。
👉 [Discordに参加する]
※ この Discord は規模を限定して運用しています。