~For an Era Where Code Generation Speed Exceeds Human Comprehension Speed~
Code generation has already outpaced human comprehension.
This is not a tooling issue. It is a structural inevitability.
As is widely recognized, there are risks in directly applying AI-generated code to production environments.
To prevent this, AI-generated code is limited to “auxiliary use” with engineers reviewing each piece, leading to a persistent state where “AI is fast, but reviews can’t keep up.” Has this become the norm?
This situation won’t change even as AI versions upgrade and performance improves.
Consequently, at least until AI completely overcomes these weaknesses and achieves human-engineer-level system-wide design adherence, development speed won’t improve despite AI’s progress.
K-MAD (Knowledge Constrained Method for AI driven Development) is, in essence, “an enforceable development methodology that focuses on methods other than full human review as a way to prevent collapse.”
“Multi-layered governance structures within the development environment and product architecture, including scripts that take over design specification reviews (both static and dynamic), are the core solution to this problem”.
Specifically, they include the following:
I am a non-engineer without skills in reading or writing code, yet using this methodology, I created project groups totaling on the order of ~70,000-80,000 lines “without code reviews” “in 8 months” (some still evolving).
(Links to the product and the GitHub repository containing the code will be provided later.)
I believe this serves as one proof of the methodology’s effectiveness.
Please examine the details below and see for yourself.
In this document, “governance” does not mean organizational policy or human management.
It refers to mechanically enforced constraints that determine whether AI-generated outputs are accepted or rejected.
The first project I began was completely solo development spanning approximately 8 months.
“If AI can write code, development should become easy (meaning even a non-engineer like myself should be able to program).”
The result was different.
This phenomenon is not about skill deficiency or tool selection issues.
It’s a structural problem existing in a dimension separate from individual code correctness.
However, because I knew nothing about system development conventions, I was reckless enough not to think it was “impossible.”
I concluded “the method is wrong.”
I first severely faced this problem during development of Rephrase, an English learning app.
In reality, each time I had AI add a feature, contradictions emerged somewhere, and the intended behavior never materialized indefinitely.
Nevertheless, Rephrase ultimately succeeded in making all features work simultaneously.
However, this was not “reproducible success.”
Not at that point.
Discomfort Became the Starting Point
From an engineer’s perspective, this system should be unstable.
Yet I was able to make it work.
That made the question more concrete:
Why can’t overall consistency be ensured in AI-generated code-based development, even when locally things appear correct?
This is not theory. Evidence follows.
Looking back, this path couldn’t be opened by a single flash of insight. It was a collection of discoveries visible only after repeated failures.
AI has learned from vast text data on the internet including specialized knowledge across all fields.
However, unless the user explicitly asks, it won’t proactively guide using that knowledge.
If you could ask from the start like “There’s this kind of structure here that contradicts the intended behavior. In such cases, what techniques exist to avoid it?”, you might get something. But as systems grow complex, if you don’t know what structure is being created behind the scenes in the first place, there’s no way to ask.
And AI will never say from its side “This form won’t work. Here’s a method.”
Partial Correctness Means Nothing Without Overall Enforceable constraints—Meaning Collapses
In this project, a UI that appeared correct locally broke invariants when randomized.
This application’s characteristics became one realization toward the principle:
“Local validity must be governed at the system level.”
Ultimately, I separated roles and authorities in the development system into the following three. “Separation of duties” was a familiar concept to me, given my profession as an internal auditor.
The third is crucial. An entity that can always say “No” when inappropriate against overall consistency.
This is not AI.
It’s scripts that compare and verify rules against evidence.
Having completed Rephrase, I was enthusiastic that I could “make anything” and decided to turn next concept into an application as well.
And that was reckless.
I remade this probably about 20 times.
Given the complexity inherent in the premise of a “system executing grammatical decomposition,” conditions making it more prone to collapse than RephraseUI when left to AI alone were clearly present from the start.
“instructional guidances to AI Weren’t Wrong”
Of course, I tried everything I could think of at the time:
・Prompt engineering (specific, bulleted, explicit prohibitions)
・Detailed design documents
・Detailed progress status
・Document accumulation of failure/success examples
・Every time opening new chats, passing them all called “loading” to ensure understanding
But at some point I realized:
The problem isn’t “instructional guidance quality.”
The problem is “absence of governance.”
Ultimately I arrived at one lesson:
“Enforceable constraints forcing compliance on AI are necessary.”
Responsibility boundaries and permitted I/O for units, defined in a “mechanically enforceable” format.
In internal control and governance, separation of duties is a crucial concept.
In practice, most of these are created and stored externally to the code: natural language specifications + static definition files (e.g., AST standards, routing rules, slot enforceable constraints, domain dictionaries). This is the principle of “Knowledge must act.”
Examples include:
AI-generated code and unit output results are not immediately treated as established facts but are handled as provisional “Claims.”
Normally, AI doesn’t seek user approval and rewrites code as it sees fit (though sometimes it does ask “Is this okay?”).
Units, without rules, might generate duplicate output information or forcefully write data in formats that cause problems.
Instead of allowing such things to “execute” immediately, they are held pending until approval is obtained. This prevents “AI output” from being surreptitiously replaced with “system fact.”
All Claims must pass through “inspection and judgment.”
Here, the following points are mechanically checked:
・Is this a permitted change?
・Does it have unexpected impact scope?
・Does it contradict the overall structure?
・Does it match “patterns that previously broke the system”?
Even if it appears to work locally and provide the requested functionality, it will be immediately rejected if it violates the overall design.
The Arbiter implements two different things for two different axes:
Both perform “mechanical rejection,” but reject different targets.
GovernanceGate determines “whether that code may be implemented.”
ClaimArbiter determines “which result to adopt (output).”
Note that this is not simply an AST linter. As I’ll explain later, my current implementation has four gate layers.
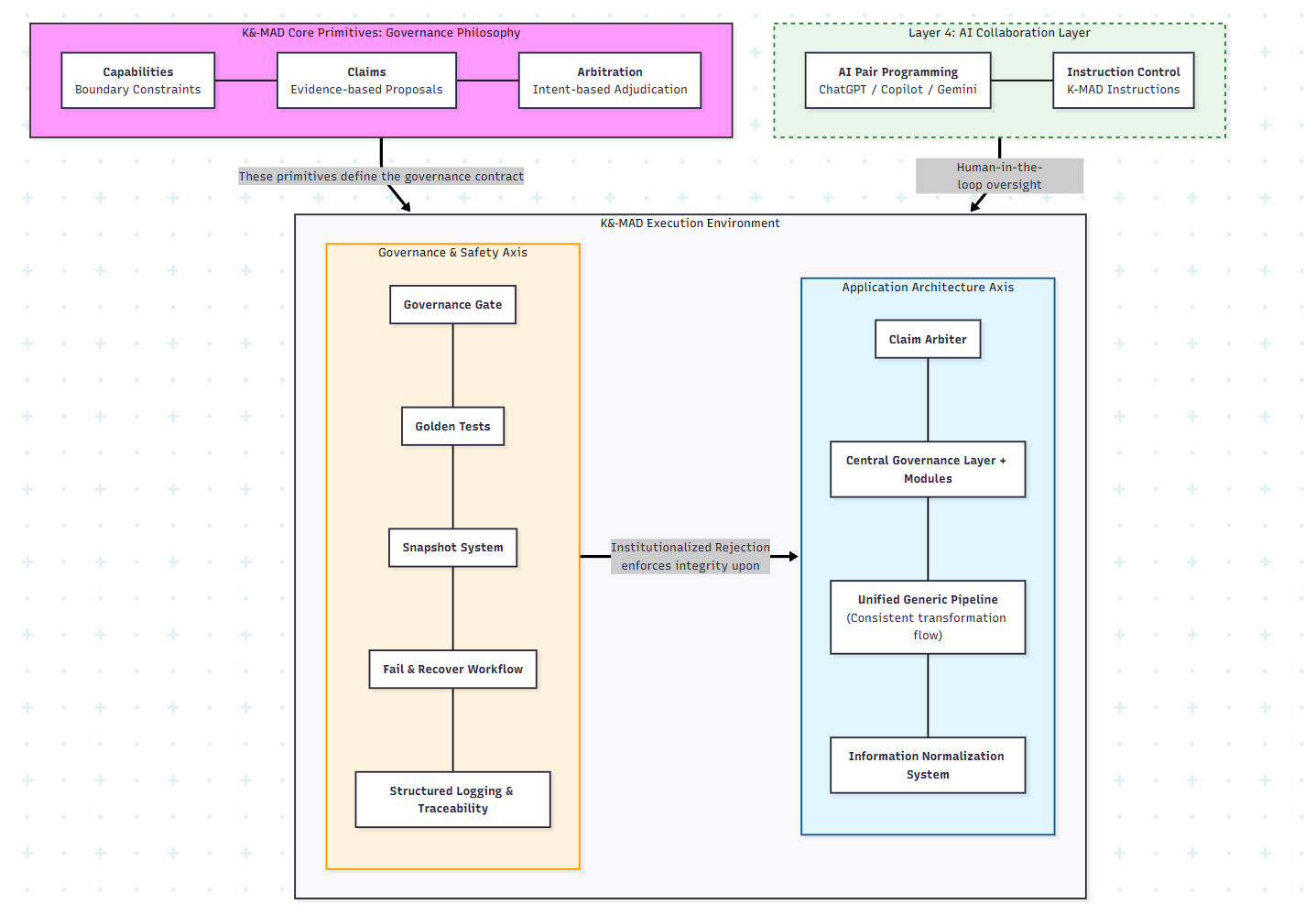
Positioning of the Three Principles
Next, I’ll show implementations to realize these principles, which exist to Enforce, Support, and Scale these “three principles.”
I believe these three principles are fundamentally what provides consistency to the entire system, and I intentionally distinguish them from implementation.
To trust and accept AI-generated code, we require objective “evidence.”
Rather than accepting it as-is, all generated code without exception is verified for validity from multiple angles by automated checking mechanisms, and is accepted only when it passes.
The governance system has two axes:
Note
This document focuses on explaining the “roles” and “design philosophy” of each component in K-MAD.
Specific implementation details such as retention periods, data formats, and acquisition timing may change depending on the operating environment and version.
For the latest behavior and detailed specifications, please refer to the AI_Controller README.
A script installed to connect with GitHub Desktop. If AI-generated code attempting to be committed contains violations, it automatically blocks saving. Violation details are displayed, and AI automatically references them and immediately begins corrections to resolve violations.
The GovernanceGate consists of the following four Layers:
def governance_gate(change):
ast_ok = enforce_ast(change, standards="ast_linter_standards.json")
flow_ok = run_golden_tests(change) # dynamic validation
domain_ok = inspect_domain_invariants(change)
arch_ok = compare_snapshots(change)
return ast_ok and flow_ok and domain_ok and arch_ok
Controls from two directions: listing/excluding violations anticipated during design and encountered during development, and enforcing “forms that must be maintained.” Prohibition enumeration and exclusion is a collection of “points,” but whitelisting covers the “surface (allowing only permitted items).”
When only looking at the structure of written code, issues like “when actually run, it doesn’t flow as intended” or “it stops here” occurred.
Therefore, emphasizing “how data actually flows,” we automatically inspect whether processing occurs in the order according to the designed flow.
Inspects whether it conforms to the specialized knowledge specific to that app (such as linguistic rules for Rephrase).
Inspection to ensure that new implementations or modifications don’t degrade the existing system. To guard against situations like “rule patterns have been deleted and reduced,” we compare with snapshots from the point we decided to protect in the past, not permitting system degradation.
This needs to be used differently depending on the application type, but for example, for “output something” types, we prepare correct data and verify operation by comparing answers. For “display something according to certain rules” types, we verify operation using tools like Playwright.
A system that can preserve snapshots of the entire system (compressed code storage) at predetermined specific timings (when GovernanceGate passes, when Golden Tests execute, etc.). Combined with Golden Tests, this identifies the save that caused errors and serves as insurance to enable reverting to code from any normal point within defined ranges.
A log to prevent AI from “forgetting past successful experiences.” The moment an error is resolved, this mechanism records logs of “what was the cause” and “how it was resolved,” reusing them as “external memory.” We set up automated template text to appear in the terminal at Golden Test completion, and when it appears, paste it into the chat field to instruct AI.
This is one countermeasure for AI being unable to retain all history due to token or memory limits. During development, the same locations break repeatedly. In such cases, having AI reference these records can lead to quick understanding of resolution methods.
A logging system to quickly identify “where and why” even if an error occurs, enabling accurate feedback to AI.
To ensure AI doesn’t get confused about “where and what to write,” while simultaneously enabling understanding of “where and what happened” in emergencies, we clearly fix the overall system structural design in advance.
Consolidates the overall “decision-making function” in one place, preventing modules from proceeding in divergent directions.
For multiple Claims from various modules (in a sense, from the AI that created them), it selects which is most appropriate for the current design based on predetermined “rules” (such as a scoring system) and decides which to execute.
The ClaimArbiter exists because in complex parse/generation pipelines, multiple units may produce plausible answers to the same matter.
Unlike GovernanceGate, this doesn’t “block commits.” Based on architectural rules, evidence, and conflict resolution, it determines which claims to output as system results and which to downgrade or discard.
def arbitrate(claims):
scored = [(score(c), c) for c in claims]
scored.sort(reverse=True)
return scored[0][1] # accept best claim; log the rest
Each component is assigned predetermined separation of duties (Capabilities) and prohibited from outputs outside their jurisdiction. This clarifies error occurrence locations, prevents errors from output contradictions/duplications, and ensures ease of correction when problems occur.
By predetermining data processing order and routes and limiting them to one (consolidating code performing the same processing to one location as much as possible, not generating duplicates), it becomes easier to “see where what is happening” and “corrections only need to be made in one place.”
By ensuring exchanged data always passes through the Central Layer, we prevent its format and storage location from becoming scattered, avoiding confusion during corrections.
“Dynamic” here doesn’t mean “the Arbiter uses scoring functions.”
It means that through Golden Tests, trace shape audits, snapshot-based degradation detection, etc., “we validate not just syntax but ‘behavior.’“ That’s what transforms a “linter” into a “gate.”
And that’s also why this governance system scales for medium to large-scale development.
It replaces the impossible requirement that “someone must completely read and understand all code AI generates” with the following enforceable thesis:
“Define enforceable constraints, enforce through evidence verification, and institutionalize ‘mechanical rejection.’”
The evidence presented below is intended to verify a single point:
“Can design specification compliance of AI-generated code be ensured without relying on human review?”
This is a project I took on as a reckless challenge before K-MAD was born, which ultimately became the catalyst for creating K-MAD.
Rephrase Project Overview
Rephrase URL: https://altheahfy.github.io/Rephrase_ui_public/training/index.html/
※ After opening the site, please select one data item from the “Select” dropdown menu and load it.
※ Currently not optimized for mobile devices.
Though I myself had no way of knowing, technically this app was an attempt to simultaneously satisfy multiple “fragile requirements”:
What Does Rephrase Do?
This Rephrase app first hides English from parts of example sentences of specific grammar that you want to practice. However, there’s a feature where illustrations concisely showing the English inserted in those locations are displayed.
In this state, it randomizes and switches sentences. Then, even with English invisible in parts, you can read aloud the entire sentence using illustrations as hints. As a result, you end up repeatedly testing your structural sense of the parts you want to practice.
If you gradually expand the parts where English is hidden, your grammatical sense is forced to expand accordingly, and you gradually acquire English through physical sensation without relying on memorization or Japanese—that’s the intended effect (applying a methodology called pattern practice).
Therefore, it was necessary to separate “the ‘hidden’ state for text data” from “the text itself dynamically inserted into slots as selected from the population as a result of randomization.”
I learned later that such combinations are considered typical “cliff edges” in frontend.
Here, AI doesn’t say:
“It breaks here,” “State-driven design is necessary.”
Actually, it’s like this:
“Understood. I’ll implement it.”
But it doesn’t actually work well. When randomizing, the English that should have been hidden gets displayed.
This means I’ve unknowingly ended up demanding something impossible from AI.
I eventually came up with a mechanism to save the “hidden” state as meta-information in HTML and reference it during regeneration.
~Rephrase’s Randomization Didn’t Work Until Governance Concepts Were Introduced into the Algorithm Itself~
In Rephrase’s randomization design initially, how to ensure semantic consistency of example sentences after randomization was a challenge.
Simply using methods like “swap subjects” or “swap verbs” obviously cannot maintain consistency.
I gave her a cup of coffee.
She gave me some money.
These are two example sentences dealing with the same SVOO grammar, but mixing them without thinking creates semantically broken sentences like:
I gave me some money.
She gave her a cup of coffee.
In the above example, in terms of system programming, it correctly selects one from the population of the S part and appropriately inserts the result. Same for the O part.
However, even if each slot individually involves “correct” processing, there’s no consistency when viewed as a whole sentence.
The Solution I Came Up With:
Since detailed explanation of linguistics or randomization algorithms themselves isn’t the purpose, I’ll state briefly:
In other words, two-stage randomization.
A system developed after completing RephraseUI to automatically structure grammatical example sentence text data into a slot database for display in RephraseUI.
Note: Beyond its current use for building Rephrase’s example database, this system may also serve as an intermediate structural layer when applying dependency-based NLP engines (e.g., spaCy) to downstream applications.
In essence, for input sentences, it recursively performs grammatical decomposition to the embedded clause level of nested structures, identifying “this is the main clause, this is the predicate, this is the object clause, this is the modifying clause, and within the main clause, this is the subject, verb,” etc.
Initially I intended to do this by manual input, but that would clearly take years. There are about 5,000 example sentences, and they’re expected to multiply via AI to around 25,000.
The moment I became conscious that “this will become a methodology,” “no, it must become one,” arrived not during RephraseUI but during development of the system I began building as its continuation.
I remade this probably about 20 times. I no longer remember the exact count.
RephraseUI was completed in about 2 months, but the Automated Sentence Structuring System remained incomplete even after half a year had passed.
After about 20 scrap-and-rebuild cycles, K-MAD was completed, and from then on I applied it to development. While only some grammar patterns are implemented yet, the implemented grammars can be processed. I’ve created a simple UI for you to try.
Automated Sentence Structuring System URL: https://altheahfy.github.io/The-Automated-Sentence-Structuring-System_Public/
Automated Sentence Structuring System Project Overview
Here, to show the changes before and after governance system construction, I’ll present a code comparison of “before” RephraseUI and “after” Automated Sentence Structuring System.
In Before, rendering, state, and side effects are mixed in the same function, creating a structure where the impact scope of changes is difficult to read.
function renderSlot(slotName, chunk_text, _parent_slot=null) {
// For Aux slot, skip text visibility check (always display)
if (slotName === "Aux") {
// Always display regardless of text visibility state
return renderSlotContent(slotName, chunk_text);
}
const slotDiv = document.getElementById(`slot-${slotName}`);
if (!slotDiv) {
console.warn(`Slot div for ${slotName} not found`);
return;
}
// Ensure slot's main display area
let mainContent = slotDiv.querySelector('.slot-main-content');
if (!mainContent) {
mainContent = document.createElement('div');
mainContent.className = 'slot-main-content';
slotDiv.appendChild(mainContent);
}
// ★ FIXED: Clear mainContent only (not sub-slots, only main)
mainContent.innerHTML = '';
// Get slot text visibility state
const showSlotText = getSlotTextVisibility(slotName);
console.log(`📌 Slot ${slotName}: showSlotText = ${showSlotText}`);
// Render main content
mainContent.innerHTML = renderSlotContent(slotName, chunk_text, showSlotText);
// Set up sub-slot toggle buttons
bindSubslotToggleButtons();
return;
}
// ✅ FIXED: Display main DOM slotPhrase (based on _parent_slot)
const mainSlotPhrase = getSlotPhraseIfAvailable(slotName, _parent_slot);
mainContent.innerHTML = renderSlotContent(slotName, chunk_text, showSlotText, mainSlotPhrase);
In After, processing is staged, and failures are observed in the same form (determined by logs and return values), creating a structure where they can be “rejected” by tests and gates.
def _execute_unified_pipeline(self, text: str, mode: str = "main") -> SlotChunkResult:
"""
Execute unified pipeline
mode: "main" (main sentence), "embedded" (embedded clause), "phrase" (phrase)
"""
self.logger.warning(f"[PIPELINE_START] mode={mode}, text='{text}'")
# 1. PhraseChunker: Extract phrases
chunker_result = self.phrase_chunker.chunk_text(text, mode)
if not chunker_result:
self.logger.warning("[CHUNKER_FAIL] PhraseChunker returned None")
return SlotChunkResult(success=False, error="PhraseChunker failed")
# 2. spaCy analysis (unified)
doc = self.spacy_processor.process_text(text)
if not doc:
self.logger.warning("[SPACY_FAIL] SpacyProcessor returned None")
return SlotChunkResult(success=False, error="SpacyProcessor failed")
# 3. Chunk mapping (unified)
chunk_map = chunker_result.chunk_map
self.logger.warning(f"[CHUNK_MAP] Extracted {len(chunk_map)} chunks")
# 4. Handler execution (unified)
handler_results = []
I realized the code generation results themselves weren’t the problem—no need to obsess over that.
The problem was in the moment that generation gets “adopted.”
AI proposes generation and modifications.
However, no mechanism exists to decide whether to accept those changes.
In human engineering, this is resolved as follows:
Of course, on the premise of non-engineers like myself developing using only AI-generated code, we cannot rely on these.
However, this isn’t a problem that “arose because I’m a non-engineer,” but from the perspective of “maximally leveraging AI generation beyond human comprehension speed,” isn’t it a problem that will become an issue in the engineering world as well?
I mentioned prompts, rule documents, and progress status sharing earlier.
I said “it’s not instructional guidance quality.”
The reason all of these failed can be stated quite simply, in a sense:
They all functioned as “non-binding requests,” but could not become “mechanical rejections” forcing system-wide behavior.
AI operates within the premise scope of words and documents given at that time (not reading every single word thoroughly either).
And it generates code it interprets as correct within those premises. But that code, in my experience, frequently violated overall design intent and specifications—that’s the fact.
There was one place where control was reliably possible.
At GitHub Desktop commit time.
I created a script that runs when clicking the “commit button,” fully scanning code written by AI. If there are rule violations, it physically rejects saving (committing).
This is the Governance Gate.
The Governance Gate does the following:
The trigger was an AST Linter suggested by ChatGPT, but recognizing it alone was insufficient, I devoted all efforts to building every governance system I could think of in parallel with the system development itself.
I shifted to a stance of “not trusting AI’s capabilities unlimitedly, but trusting AI within a ‘mechanism’ that controls it.”
The governance system introduced doesn’t need to be implemented all at once.
It’s a methodology where “governance can be strengthened progressively.”
I call this method K-MAD (Knowledge Constrained Method for AI driven Development).
It’s a technique for building together with AI while rejecting the premise often considered default: “working code = safe code.”
To maximally leverage AI generation, accurately grasp its “weakness (large-scale system consistency),” defend against it with mechanisms, and reduce human review burden.
By establishing mechanisms on these two axes of “Governance & Security” and “Architecture,” AI output becomes dramatically more stable and aligned with design specifications. This is K-MAD’s proposed new form of “co-creation” for the AI era.
K-MAD doesn’t attempt to internalize things into AI.
It’s a way of thinking about “where Judgment resides.”
In an era where “generation” scales faster than “comprehension,” relying on human code reading as the primary safety mechanism makes human “understanding” the bottleneck.
What prevented collapse wasn’t seeking more capable AI. It was the resolute stance of treating all outputs as “Claims” and imposing governance through “enforceable constraints” to preserve architectural intent for their acceptance.
K-MAD doesn’t deny code reviews.
However, it’s a methodology to reduce review burden by supplementing with alternative governance means against scales and complexities where reviews alone can no longer guarantee safety.
—Because “generation” has overtaken “comprehension.”
AI_Controller URL: https://github.com/altheahfy/AI_Controller/
After publishing this document, I observed an unexpected reaction and hereby provide an additional report.
An AI engaged in a large-scale project concluded from a third-party standpoint that “to prevent future collapse of this project,
K-MAD (and its governance) should be immediately implemented.”
(Excerpts of relevant portions and screenshots are posted in the AI_Controller repository and Discord.)
※ Regarding Line Counts
Line counts shown in this document are based on executable source code lines (LOC), targeting only executable code in Python / JavaScript.
Depending on scope, this includes active runtime code and surrounding configuration and artifacts.
If you want to apply this to an actual project or confirm whether K-MAD fits your situation,
please contact us here.
👉 https://altheahfy.github.io/Contact/#Contact/Conversations/
For ongoing discussion about K-MAD,
we’ve prepared a small, limited Discord.
👉 [Join Discord]
※ This Discord is operated with limited scale.